There currently exists no data set through which to effectively communicate the case for the family as an emotional unit to mainstream science. In fact, there exists no data model, let alone a data set, to replicate Bowen’s original research and claims. Nevertheless, his theory remains intriguing because it does deal with potentially testable concepts. This is an essential achievement considering that the state of the art for clinical theory deals with untestable subjective concepts.
If Freud’s key mistake was using discrepant models from human history and culture to describe nature, then perhaps Bowen’s key mistake was not recording or retaining the hard data to support his claims in a communicable way. Both theorists produced key observations about human functioning not previously dealt with by science. Bowen’s observations remain not dealt with.
Seeing Iain Couzin’s fish models changed my conception of biological research. For three years now, I have been convinced that computerized analysis and prediction is required to not just make up for the lack of a data set on the family as an emotional unit, but to advance research on the phenomenon with all its complexity. This requires exceedingly large sample sizes of exceedingly complex quantitative data. This in turn requires a human to identify what quantitative data can record what theory describes. “Machine learning” can then produce a predictive model by making sense of those complex data where a human cannot.
Identifying such a data model requires getting crystal clear on what theory says. After three grueling years and with the help of others, I am going to present a first step for such a model. While guided by theory, each variable in this should not assume theory, but taken together ought to test theory.
At its core is a formalization of the “toward or away move” along with shifts in arousal (i.e. “anxiety”). The toward or away move is proposed as the atomic operation of emotional function. This atomic operation gives rise to the structural molecule of the emotional system: the triangle. A “toward” move is approaching contact in general or comfortable closeness in relation to one or more others. An “away” move is avoiding contact in general or uncomfortable tension in relation to one or more others. Shifts up or down in arousal as a result of each move are tracked separately for each individual. A triangle would emerge from the data when a person makes an away with one person in the same move as a toward with another. This makes possible a quantitative definition of differentiation for research, as A) an overall increase in toward moves without a compensating decrease in away moves, along with B) a moderating effect on arousal.
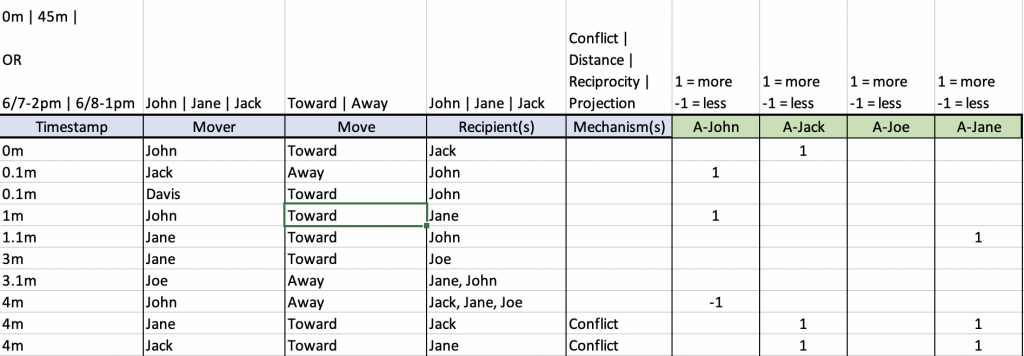
The data model fits into a simple spreadsheet. It tracks a series of toward and away moves for a set of people dealing with an issue over a limited period of time.
Such data ought to reveal a number of Markovian probabilities. That is, the chance of making one of a limited set of decisions in a chain reaction. The list of probabilities in this model are:
- Whether any person moves next or not (satisfaction/comfort variable).
- Which person moves next.
- What move they make (toward or away).
- Who the move is in relation to.
- Whether any person has a shift in arousal.
- What that shift in arousal will be (up or down).
This set of probabilities would then define the algorithm of an agent-based simulation of family emotional process. Refined over time, this simulation would evolve into the predictive instrument of Bowen theory.
Hypothetically, a few sequences ought to be enough to be useful clinically. This should be possible if the data model is accurate to theory, and if theory is accurate to the human phenomenon. I myself have made useful discoveries after looking at only a couple of such sequences from a single family.
Thus, if there is anything to this definition of the atomic operation of emotional process, the data model would standardize the collection of case data in the Family Diagram app over one family issue as well as over an entire family history. This would enable the app to crowd-source anonymous case data for a comprehensive family research database. Such a database would make possible the testing of independent variables with Bowen theory, such as position in the reproductive hierarchy, or when of the four binding mechanisms (distance; conflict; overfunctioning/underfunctioning; child-focus) is used, which mechanism is used, by whom, or the modulation of a clinical symptom, and others.
In any case, it all ought to be possible to let the merciless data speak for itself.